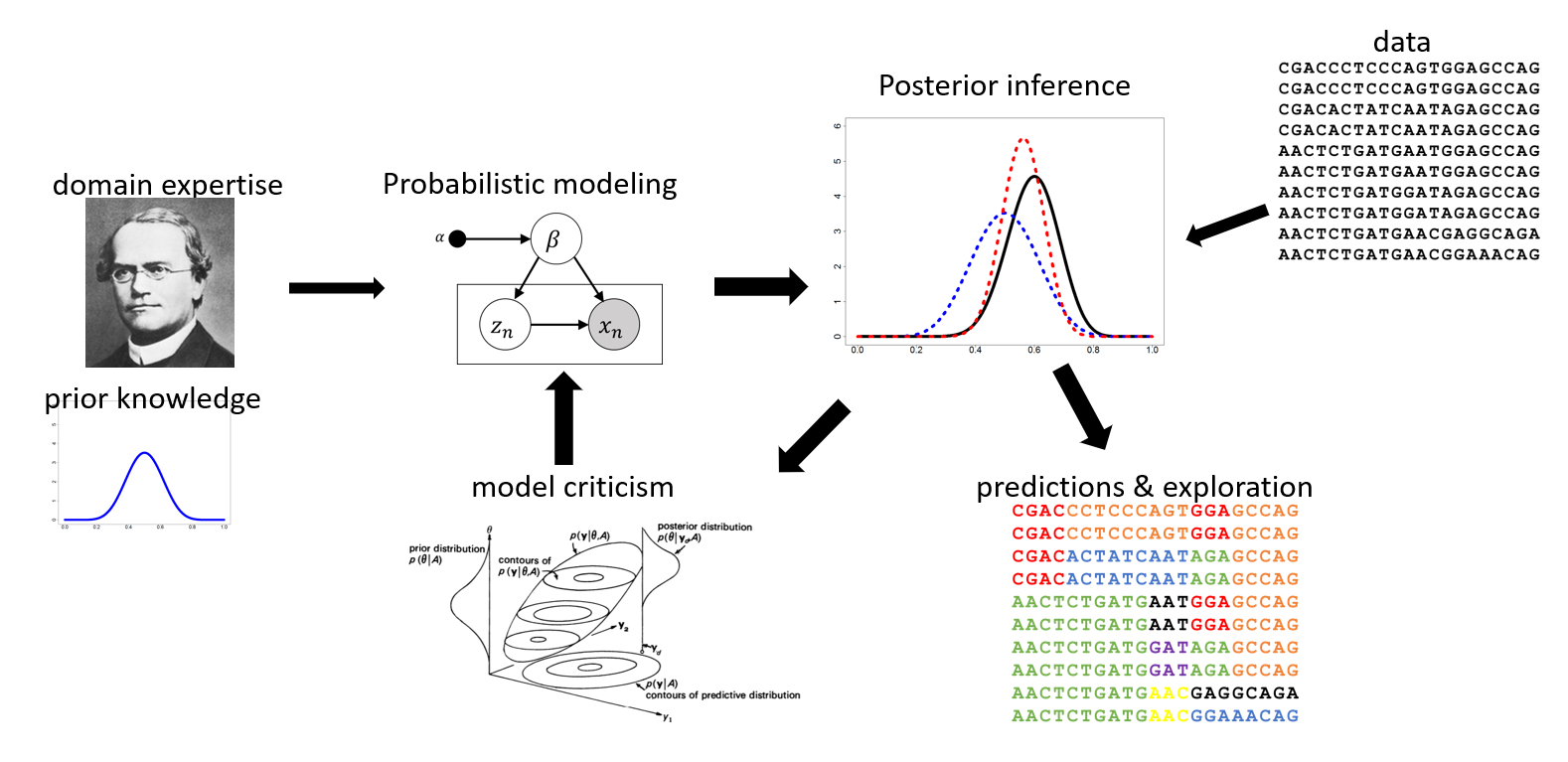
Bayesian Machine Learning
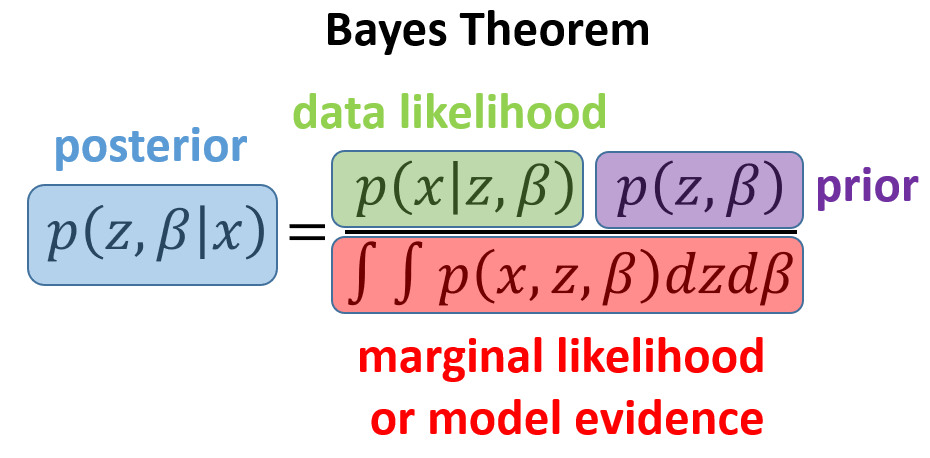 The probabilistic (or Bayesian) machine learning paradigm provides a unifying methodology for reasoning about uncertainty in modeling complex data.
In this class, we will cover the three fundamental components of this paradigm: probabilistic modeling, inference algorithms, and model checking.
See the syllabus.
The probabilistic (or Bayesian) machine learning paradigm provides a unifying methodology for reasoning about uncertainty in modeling complex data.
In this class, we will cover the three fundamental components of this paradigm: probabilistic modeling, inference algorithms, and model checking.
See the syllabus.
We will reinforce class lectures by developing a research-quality project (ideally connected to your research) on real data that implements this probabilistic framework from problem specification to model checking. To realize this, you should be comfortable with (or willing to learn):
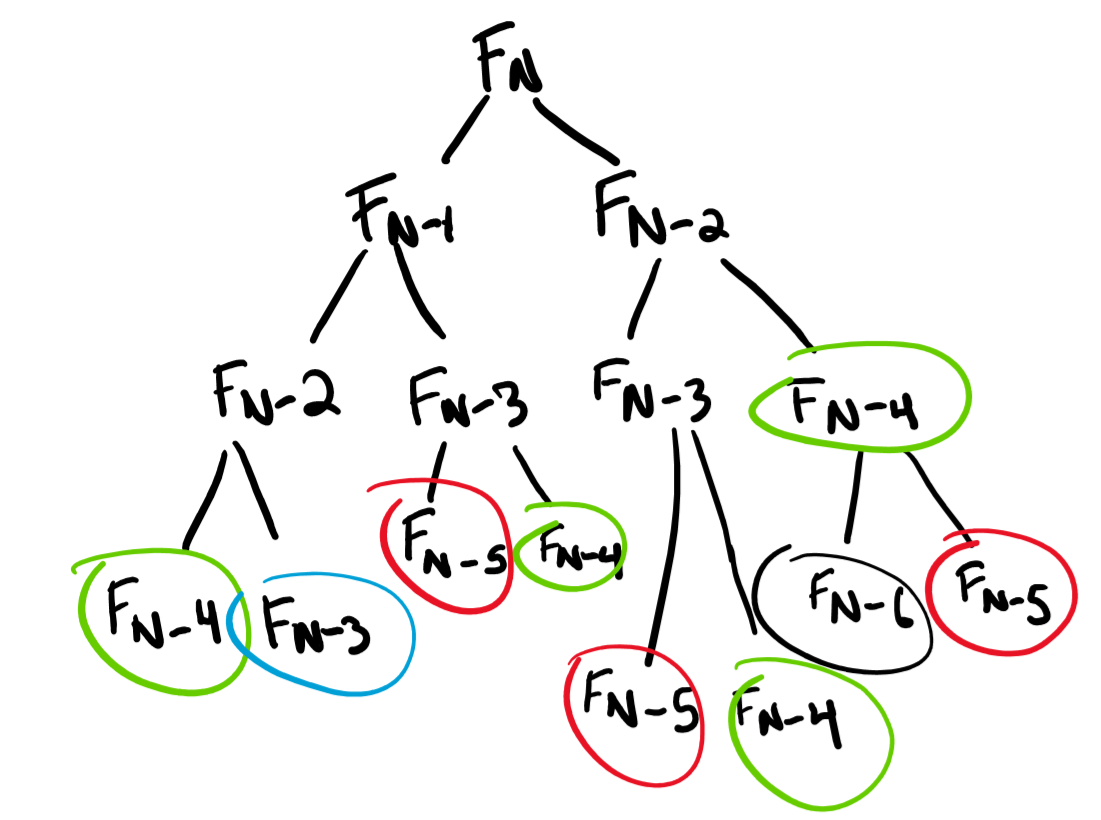
Algorithms and Complexity
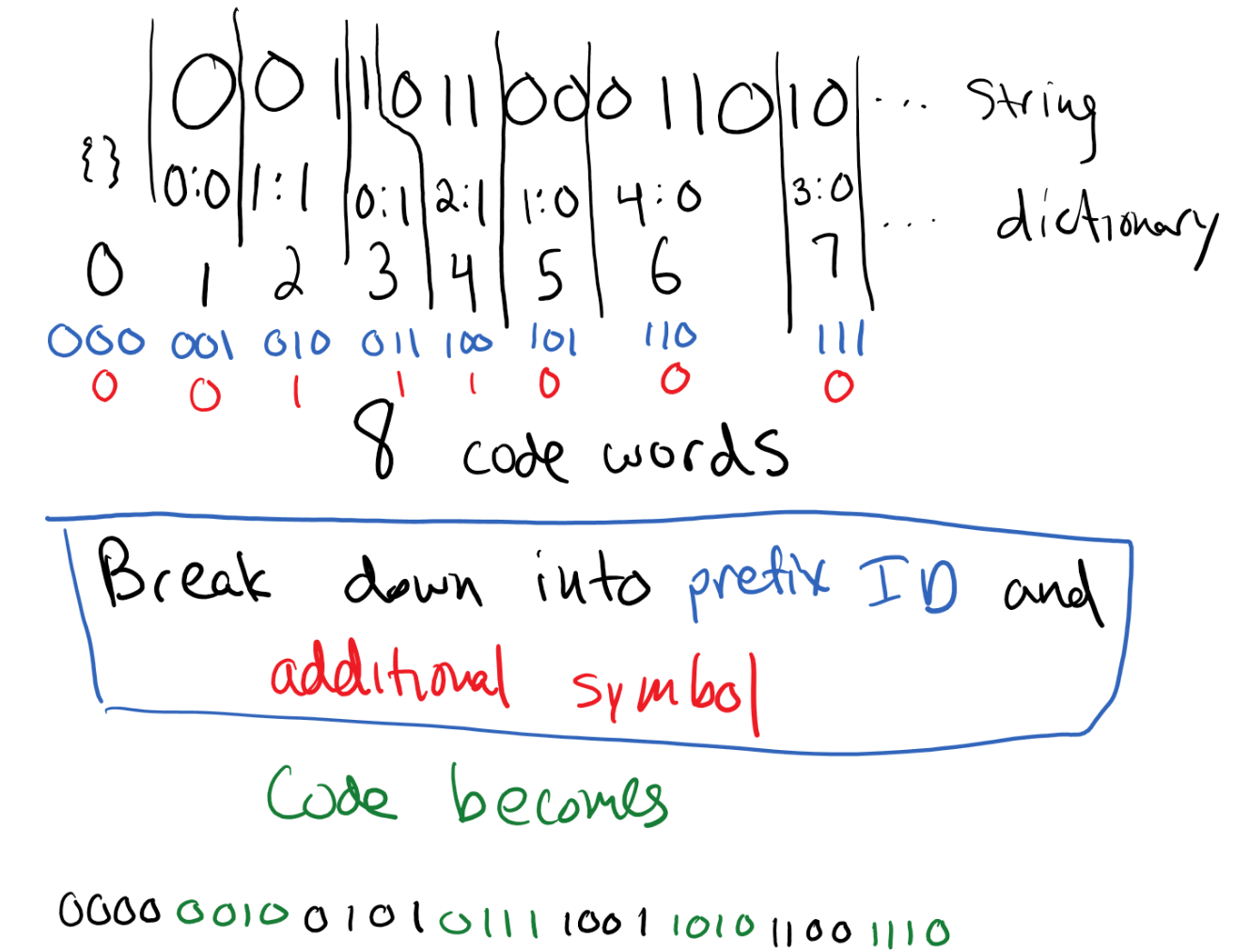 Algorithmic thinking is a powerful way to view the field of computer science and algorithms themselves are at the core of scientific endeavours across many disciplines.
For example, careful algorithmic design and implementation is what enabled researchers at Celera Genomics to assemble tens of millions of DNA reads into the sequence of the human genome.
This course will cover algorithmic design and analysis, advanced data structures, and computational complexity.
Specific topics include divide-and-conquer, dynamic programming, greedy, and graphical algorithmic design techniques; seminal algorithms, e.g., sorting, hashing, network flow; advanced data structures, e.g., search trees, heaps; NP-completeness and intractability; and, time permitting, more advanced topics.
See the syllabus.
Algorithmic thinking is a powerful way to view the field of computer science and algorithms themselves are at the core of scientific endeavours across many disciplines.
For example, careful algorithmic design and implementation is what enabled researchers at Celera Genomics to assemble tens of millions of DNA reads into the sequence of the human genome.
This course will cover algorithmic design and analysis, advanced data structures, and computational complexity.
Specific topics include divide-and-conquer, dynamic programming, greedy, and graphical algorithmic design techniques; seminal algorithms, e.g., sorting, hashing, network flow; advanced data structures, e.g., search trees, heaps; NP-completeness and intractability; and, time permitting, more advanced topics.
See the syllabus.
The prerequisites for this class include CSE 2050 or 2100, and 2500. CSE 3500 is only open to students in the School of Engineering, Cognitive Science majors, and declared Computer Science minors.